

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 이차전지
- 미래에셋 장학생
- set add
- Deeplearning
- fatigue fracture
- 양극재
- anaconda 가상환경
- 유럽
- 미래에셋해외교환
- set method
- 2022년
- fluent python
- m1 anaconda 설치
- 특별 메소드
- 유럽 교환학생
- 딥러닝
- 선형회귀
- Andrew ng
- Python
- li-ion
- 청춘 화이팅
- 나의23살
- cost function
- special method
- gradient descent
- electrochemical models
- Linear Regression
- Machine learning
- 교환학생
- 오스트리아
- Today
- Total
Done is Better Than Perfect
01. introduction 본문
1. Machine Learning의 정의
- [Arthur Samuel의 정의] 프로그래밍 없이도 컴퓨터 스스로 학습할 수 있게 만들어 주는 연구
" Machine Learning is a field of study that gives computers the ability to learn without being explicitly programmed."
- [Tom Mitchell의 정의] 작업 T가 있고, P로 성능이 측정될 때, 그 P가 경험 E를 통해 학습하며 향상되는 프로그램
Tom Mitchell provides a more modern definition:
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
응용분야
- data mining
- 손으로 프로그래밍할 수 없는 분야 (자율주행 자동차, 자연어 처리, 영상처리)
- Self-customizing programs
- understanding human learning(brain, real AI)
2. Machine Learning 알고리즘
- Supervised Learning(지도 학습) : 정답을 알고 있는 데이터를 기반으로 예측 모델을 만드는 ML
- Unsupervised Learning(비지도 학습) : 정답을 모르는 데이터에서 유용한 정보를 분류, 추출하는 ML
- 추가적으로 사용자가 관심을 가질만한 정보를 추천하는 Recommender System도 ML의 한 분야이다.
3. Supervised Learning (지도 학습)
정답(label)이 있는 dataset을 사용하여 컴퓨터를 학습시키는 방법. data set의 형태는 [data(input) - label(output)]으로 주어진다.
따라서 label이 정해지지 않은 data를 사용하여 label을 예측한다.
Supervised Learning 의 세부 분류로는 'regression'과 'classification'이 있다.
regression : 연속적인(continuous) 결과값 예측
ex) 부동산 집 값 예측

강의의 예제에서 input은 집의 넓이이고, output은 집의 가격이다.
output에 해당하는 집의 가격은 연속적인 값을 가지므로
이는 regression 문제이다.
classification : 이산적인(descrete) 결과값 예측
ex ) 종양 크기에 따른 양성/음성 예측
그림의 예제에서
input은 종양의 크기이고, output인 진단결과이다.
output에 해당하는 진단결과가 양성/음성으로 discrete category이므로
이는 classification 문제이다.
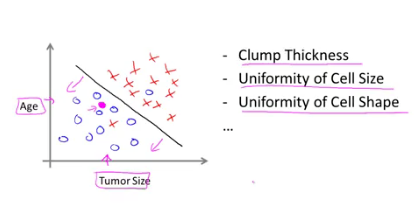
아래 그래프처럼 종양의 크기에 나이 속성을 더하여 진단결과를 내릴 수 있다.
추가적으로 Clump 두께, 종양 세포크기의 균일함, 모양의 균일함 등 다양한 속성(feature)도 함께 고려하여 분류할 수 있다.
이렇듯 속성의 개수가 증가할수록, 그래프의 축(차원)의 개수 또한 증가한다. 증가한 차원에서 선형의 직선으로 구분짓는 함수를 찾는 것이 예측 모델을 찾는 것이라 할 수 있다.
4. Unsupervised Learning (비지도 학습)
정답(label)이 없는 dataset을 사용하여 컴퓨터를 학습시키는 방법. data set의 형태는 [data(input)]으로 주어진다.
따라서 데이터에 숨겨진 구조나 특징을 발견하는 데 사용된다.
- clustering : 주어진 데이터를 n개의 카테고리로 군집화
- non-clustering : cocktail party problem - 칵테일 파티장 녹음데이터에서 특정 음성만 분리해냄
참고 문헌
'🤖 AI > Machine Learning' 카테고리의 다른 글
| 04. Logistic Regression (1) | 2022.03.23 |
|---|---|
| 03. Linear Regression with Multiple Variable (1) | 2022.02.10 |
| 02. Linear regression with one variable (1) | 2022.02.04 |
| Machine Learning 정리 (0) | 2022.01.20 |
| 추천 시스템이란 (0) | 2022.01.05 |

