
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- gradient descent
- special method
- Linear Regression
- 양극재
- 특별 메소드
- 유럽 교환학생
- 나의23살
- set method
- cost function
- Deeplearning
- fluent python
- 이차전지
- 미래에셋 장학생
- 최대공약수
- 교환학생
- Machine learning
- Python
- 선형회귀
- 최소제곱법
- 2022년
- 미래에셋해외교환
- Andrew ng
- 최소공배수
- 유럽
- 딥러닝
- set add
- anaconda 가상환경
- m1 anaconda 설치
- 오스트리아
- 청춘 화이팅
- Today
- Total
Done is Better Than Perfect
[딥러닝] 4. 딥러닝 모델 학습의 문제점 pt.1 : 최적화 알고리즘 본문
SGD의 한계점
딥러닝 모델 학습은 아래와 같은 문제점이 있다.
1. 학습 속도 문제와 최적화 알고리즘
2. 기울기 소실 문제와 방지 기법
3. 초기값 설정 문제와 방지 기법
4. 과적합 문제와 방지 기법
딥러닝 모델 학습의 문제점에 대해 자세히 알아보고, 이를 해결하기 위해 나온 방법들에 대해 알아보겠다.
딥러닝 모델 학습의 문제점
실생활 문제 데이터의 차원이 증가하고, 구조가 복잡해짐에 따라 딥러닝 모델 학습에서 많은 문제가 초래된다.
1. 학습 속도 문제 : 데이터의 개수가 폭발적으로 증가하여 딥러닝 모델 학습 시 소요되는 시간도 함께 증가
2. 기울기 소실 문제 (gradient vanishing) : 더 깊고, 넓은 망을 학습시키는 과정에서 출력값과 멀어질수록 학습이 잘 안되는 현상 발생
- 기울기 소실 = 기울기가 0으로 수렴
- 기울기는 backpropagation으로 학습함
- output layer에서 멀어질수록 이전의 gradient를 계속해서 곱하기 때문에 끝에 갈수록 (출력값에서 멀어질수록) 거의 0으로 수렴
(gradient가 0.1 이 나올 경우, 이 기울기가 계속해서 곱해지면 0에 가까워짐) - input layer와 가까운 파라미터에 대해서는 학습이 잘 안됨
3. 초기값 설정 문제 : 초기값 설정 방식에 따른 성능 차이가 매우 크게 발생
4. 과적합 문제 : 학습 데이터(train data)에 모델이 과하게 최적화되어 테스트 데이터(test data)에 대한 모델 성능 저하
1. 학습 속도 문제와 최적화 알고리즘
학습 속도 문제
- 발생 원인 : 전체 학습 데이터셋을 사용(Full batch)하여 손실함수를 계산하기 때문에 계산량이 너무 많아짐
- 해결 방법 : 전체 데이터가 아닌 부분 데이터(mini-batch)만을 사용하여 손실함수 계산 > SGD (Stochastic Gradient Descent)
[ Gradient Descent VS Stochastic Gradient Descent ]
| Gradient Descent (GD) | 전체 학습 데이터셋을 사용(Full batch)하여 손실함수를 계산 |
| Stochastic Gradient Descent (SGD) | 전체 데이터대신 일부 데이터의 모음인 미니 배치(mini-batch)에 대해서만 손실함수 계산 |


SGD 알고리즘
- GD보다 훨씬 계산 속도가 빠르기 때문에 같은 시간에 더 많은 step 갈 수 있음
- 한계 : Gradient 방향성 문제 (SGD는 gradient 값 계산 시, mini-batch에 따라 gradient 방향의 변화가 큼)
Learning rate 설정 문제 > 적합한 learning rate를 찾기 위해 다양한 최적화 알고리즘 등장함

- SGD 알고리즘의 한계점과 그 해결 방안
| SGD의 한계점 | 한계점을 보완한 최적화 알고리즘 |
| Gradient 방향성 설정 | Momentum, Adam |
| Learning rate 설정 | Adagrad, RMSProp, Adam |

- momentum : 과거에 이동했던 방식을 기억하면서 그 방향으로 일정 정도를 추가적으로 이동하는 방식 (gradient의 방향성 설정)

- AdaGrad(Adaptive Gradient) :
많이 변화하지 않은 변수들은 learning rate를 크게 하고, 많이 변화했던 변수들은 learning rate를 작게 하는 것
과거의 기울기를 제곱해서 계속 더하기 때문에 학습이 진행될수록 갱신 강도가 약해짐
- RMSProp :
무한히 학습하다보면 순간 갱신량이 0에 가까워 학습이 되지 않는 Adagrad의 단점 해결
과거의 기울기는 잊고 새로운 기울기 정보를 크게 반영 - Adam : Momentum + RMSProp -> 가장 발전된 최적화 알고리즘
[ 다양한 최적화 알고리즘 요약 ]
| 최적화 알고리즘 | 설명 |
| (GD) Gradient Descent | 모든 데이터(Full batch)를 검토한 뒤 방향 찾기 |
| (SGD) Stochastic Gradient Descent | Mini batch를 사용하여 검토한 뒤 자주 방향 찾기 |
| Momentum | 전에 이동했던 gradient를 참고하여 업데이트 |
| Adagrad | 가중치의 변화량에 따라 learning rate 조절 |
| RMSProp | Adagrad의 학습을 진행할수록 줄어들 수 있는 learning rate 문제 해결 |
| Adam | Momentum의 장점과 RMS Prop의 장점 결합 |
앞선 최적화 알고리즘을 코드로 구현해보자.
1. GD vs SGD 구현
- GD (Gradient Descent):
- 시작 지점에서 기울기의 반대 방향으로 하강하면서 손실 함수(loss function) 최소화하는 지점을 찾기 위한 가장 직관적인 방법
- 전체 데이터 셋을 가지고 학습하게 되면 안정적이긴 하지만, 계산량과 학습 비용이 많아짐
- SGD (Stochastic Gradient Descent):
- 전체 데이터 셋이 아닌, 무작위로 뽑은 데이터들에 대한 Gradient Descent를 진행, 이를 반복하여 정확도를 찾아나감
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
tf.random.set_seed(123)
# 데이터를 전처리하는 함수 - one hot encoding
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
''' 1. GD를 적용할 모델 생성 '''
def GD_model(word_num):
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=32, input_shape =(word_num,), activation='relu'),
tf.keras.layers.Dense(units=32, activation = 'relu'),
tf.keras.layers.Dense(units=1, activation = 'sigmoid')
])
return model
''' 2. SGD를 적용할 모델을 GD를 적용할 모델과 (비교를 위해) 동일하게 생성 '''
def SGD_model(word_num):
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=32, input_shape =(word_num,), activation='relu'),
tf.keras.layers.Dense(units=32, activation = 'relu'),
tf.keras.layers.Dense(units=1, activation = 'sigmoid')
])
return model
'''
3. 두 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가
Step01. GD 함수와 SGD 함수를 이용해 두 모델을 불러오기
Step02. 두 모델의 손실 함수, 최적화 알고리즘, 평가 방법 설정
Step03. 두 모델을 각각 학습시킴.
GD를 적용할 경우 학습 시, 전체 데이터 셋(full-batch) 사용(batch_size를 전체 데이터 개수로 설정)
SGD를 적용할 경우 학습 시, 미니 배치(mini-batch) 사용(batch_size를 전체 데이터 개수보다 작은 수로 설정)
Step04. 학습된 두 모델을 테스트하고 binary crossentropy 값
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러온 후, 전처리
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
# 데이터 전처리
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
gd_model = GD_model(word_num) # GD를 사용할 모델
sgd_model = SGD_model(word_num) # SGD를 사용할 모델
gd_model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy','binary_crossentropy'])
sgd_model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy','binary_crossentropy'])
# 모델 구조 확인
gd_model.summary()
sgd_model.summary()
# batch_size로 GD, SGD 모델 구현
gd_history = gd_model.fit(train_data, train_labels, epochs=20, batch_size=data_num, validation_data = (test_data, test_labels), verbose = 0)
print('\n')
sgd_history = sgd_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose = 0)
scores_gd = gd_history.history['val_binary_crossentropy'][-1]
scores_sgd = sgd_history.history['val_binary_crossentropy'][-1]
print('\nscores_gd: ', scores_gd)
print('scores_sgd: ', scores_sgd)
Visulaize([('GD', gd_history),('SGD', sgd_history)])
return gd_history, sgd_history
if __name__ == "__main__":
main()
[ 코드 실행 결과]
- scores_sgd의 실행 결과(loss function)가 더 낮음
- 즉, sgd가 더 최적화가 잘 되었음을 검증할 수 있음
### output ###
scores_gd: 0.6955338
scores_sgd: 0.63184285
TIP! 모델 학습(fit) 과정에서 verbose 변수를 활용하면 모델의 학습 과정 기록을 간단하게 표현할 수 있음.
- verbose = 0: 기록을 나타내지 않음.
- verbose = 1: 진행 바 형태의 학습 과정 기록을 나타냄.
- verbose = 2: epoch 당 1줄의 학습 과정 기록을 나타냄.
2. Momentum 구현
SGD는 손실 함수(loss function)의 최솟값에 도달하는 동안 Gradient가 진동하여 최적값에 도달하기까지의 시간이 오래 걸리는 단점이 있음. 이를 보완하기 위해 사용되는 momentum 기법은 관성의 개념을 이용해 최적값에 좀 더 빠르게 도달할 수 있도록 함
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
''' 1. 모멘텀(momentum)을 적용/비적용할 하나의 모델 생성 '''
def Momentum_model(word_num):
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=32,input_shape=(word_num,), activation='relu'),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
return model
''' 2. 두 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가
Step01. Momentum_model 함수를 이용해 두 모델을 불러옴
Step02. 두 모델의 손실 함수, 최적화 알고리즘(모멘텀 유무), 평가 방법 설정
Step03. 두 모델을 각각 학습시킴
Step04. 학습된 두 모델을 테스트하고 binary crossentropy 값 출력
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
sgd_model = Momentum_model(word_num) # 모멘텀을 사용하지 않을 모델
msgd_model = Momentum_model(word_num) # 모멘텀을 사용할 모델
sgd_opt = tf.keras.optimizers.SGD(lr=0.01, momentum=0) # 모멘텀 사용X
sgd_model.compile(loss='binary_crossentropy', optimizer=sgd_opt, metrics=['accuracy','binary_crossentropy'])
msgd_opt = tf.keras.optimizers.SGD(lr=0.01, momentum=0.9)# 모멘텀 사용O
msgd_model.compile(loss='binary_crossentropy', optimizer=msgd_opt, metrics=['accuracy','binary_crossentropy'])
sgd_model.summary()
msgd_model.summary()
sgd_history = sgd_model.fit(train_data, train_labels, epochs=20, batch_size = 500, validation_data=(test_data, test_labels), verbose=0)
print('\n')
msgd_history = msgd_model.fit(train_data, train_labels, epochs=20, batch_size = 500, validation_data=(test_data, test_labels), verbose=0)
scores_sgd = sgd_model.evaluate(test_data, test_labels)
scores_msgd = msgd_model.evaluate(test_data, test_labels)
print('\nscores_sgd: ', scores_sgd[-1])
print('scores_msgd: ', scores_msgd[-1])
Visulaize([('SGD', sgd_history),('mSGD', msgd_history)])
return sgd_history, msgd_history
if __name__ == "__main__":
main()
[ 코드 실행 결과]
- scores_msgd의 실행 결과(loss function)가 더 낮음
- 즉, momentum을 사용한 sgd가 더 최적화가 잘 되었음을 검증할 수 있음
### output ###
scores_sgd: 0.6292245
scores_msgd: 0.56693166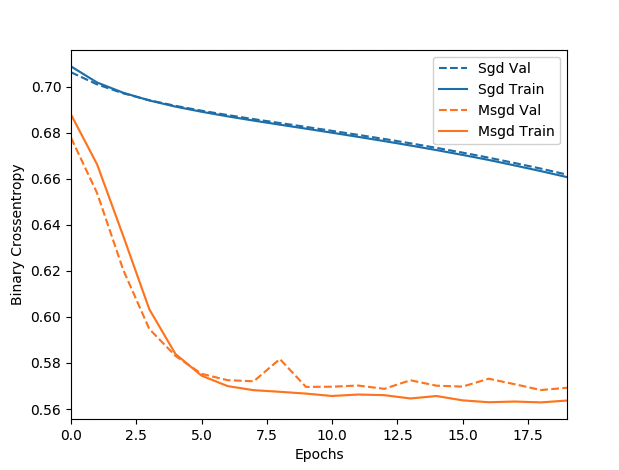
3. 최적화 알고리즘 구현 - Adagrad, RMSprop, Adam
- Adagrad(Adaptive Gradient):
- 손실 함수(loss function)의 값을 최소로 만드는 최적의 가중치를 찾아내기 위해 learning rate를 조절해 하강하는 방법 중 하나
- 기존 방식이 가중치들의 업데이트를 같은 속도로 한꺼번에 하는 방법이었다면, Adagrad는 가중치 각각의 업데이트 속도를 데이터에 맞추어(adaptively) 계산해 적절한 learning rate로 하강
- tf.keras.optimizers.Adagrad(lr, epsilon, decay)
- RMSprop:
- 학습이 진행될수록 가중치 업데이트 강도가 약해지는 Adagrad의 단점을 보완하고자 제안된 방법
- RMSProp은 과거의 gradient 값은 잊고 새로운 gradient 값을 크게 반영해서 가중치를 업데이트
- tf.keras.optimizers.RMSprop(lr)
- Adam:
- 최적화 알고리즘 중 가장 발전된 기법
- RMSProp과 모멘텀(momentum)을 함께 사용하여, 진행 방향과 learning rate 모두를 적절하게 유지하면서 학습할 수 있음.
- tf.keras.optimizers.Adam(lr, beta_1, beta_2)
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
''' 1. Adagrad, RMSprop, Adam 최적화 알고리즘을 적용할 하나의 모델 생성 '''
def OPT_model(word_num):
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=32, input_shape=(word_num,), activation='relu'),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
return model
''' 2. 세 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가
Step01. OPT_model 함수를 이용해 세 모델을 불러옴(모두 동일한 모델)
Step02. 세 모델의 손실 함수, 최적화 방법, 평가 방법 설정
Step03. 세 모델을 각각 학습시킴.
Step04. 세 모델을 테스트하고 binary crossentropy 점수를 출력
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
adagrad_model = OPT_model(word_num) # Adagrad를 사용할 모델
rmsprop_model = OPT_model(word_num) # RMSProp을 사용할 모델
adam_model = OPT_model(word_num) # Adam을 사용할 모델
# 최적화 방법을 다르게 설정 -> Adagrad, RMSProp, Adam
adagrad_opt = tf.keras.optimizers.Adagrad(lr=0.01, epsilon=0.00001, decay=0.4)
adagrad_model.compile(loss='binary_crossentropy', optimizer=adagrad_opt, metrics=['accuracy','binary_crossentropy'])
rmsprop_opt = tf.keras.optimizers.RMSprop(lr=0.001)
rmsprop_model.compile(loss='binary_crossentropy', optimizer=rmsprop_opt, metrics=['accuracy','binary_crossentropy'])
adam_opt = tf.keras.optimizers.Adam(lr=0.01, beta_1=0.9, beta_2=0.999)
adam_model.compile(loss='binary_crossentropy', optimizer=adam_opt, metrics=['accuracy','binary_crossentropy'])
# 모델 구조 출력
adagrad_model.summary()
rmsprop_model.summary()
adam_model.summary()
adagrad_history = adagrad_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data=(test_data, test_labels), verbose=0)
print('\n')
rmsprop_history = rmsprop_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data=(test_data, test_labels), verbose=0)
print('\n')
adam_history = adam_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data=(test_data, test_labels), verbose=0)
scores_adagrad = adagrad_model.evaluate(test_data, test_labels)
scores_rmsprop = rmsprop_model.evaluate(test_data, test_labels)
scores_adam = adam_model.evaluate(test_data, test_labels)
print('\nscores_adagrad: ', scores_adagrad[-1])
print('scores_rmsprop: ', scores_rmsprop[-1])
print('scores_adam: ', scores_adam[-1])
Visulaize([('Adagrad', adagrad_history),('RMSprop', rmsprop_history),('Adam', adam_history)])
return adagrad_history, rmsprop_history, adam_history
if __name__ == "__main__":
main()
[ 코드 실행 결과]
- Adam의 성능이 제일 좋고, 그 다음 RMSProp, Adagrad 순으로 성능이 좋다.
### output ###
scores_adagrad: 0.6891311
scores_rmsprop: 0.56989825
scores_adam: 0.58943623
'공부 > 딥러닝' 카테고리의 다른 글
| [딥러닝] 6. 딥러닝 모델 학습의 문제점 pt.3 : 과적합 (0) | 2024.06.22 |
|---|---|
| [딥러닝] 5. 딥러닝 모델 학습의 문제점 pt.2 : 기울기 소실, 가중치 초기화 방법 (1) | 2024.06.12 |
| [딥러닝] 3. 딥러닝 모델 구현 (선형 회귀, 비선형 회귀 모델 구현) (0) | 2024.06.08 |
| [딥러닝] 2. Backpropagation의 학습 (0) | 2024.06.07 |
| [딥러닝] 1. Perceptron (0) | 2024.06.05 |



