
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Machine learning
- 양극재
- 유럽
- 교환학생
- cost function
- li-ion
- set add
- 2022년
- special method
- 특별 메소드
- gradient descent
- Deeplearning
- anaconda 가상환경
- 유럽 교환학생
- 딥러닝
- fatigue fracture
- 이차전지
- 선형회귀
- fluent python
- set method
- Python
- m1 anaconda 설치
- Linear Regression
- Andrew ng
- 미래에셋 장학생
- 미래에셋해외교환
- electrochemical models
- 오스트리아
- 나의23살
- 청춘 화이팅
- Today
- Total
Done is Better Than Perfect
[딥러닝] 7. CNN 본문
1. 이미지와 Convolution 연산
기존의 딥러닝에서 사용하는 Fully-connected Layer는 1차원 데이터 (선형 데이터)를 input으로 요구함
- 이미지를 단순하게 1차원으로 바꾸면 2차원 상에서 가지는 정보 (사물 간의 거리 관계, 색의 변화 등)를 포기해야 함
- 즉, 공간 정보 (spatial information)가 무너짐 (-> FC layer로 이미지 데이터를 처리할 수 없음)
따라서 이미지 처리에 특화된 딥러닝 모델 등장 -> CNN (Convolutional Neural Network)
- CNN의 대표 구성요소
- Convolutional Layer
- Pooling Layer
- 분류기 (classifier) : fully-connected layer로 구성
[ Convolution 연산 ]
- CNN을 구현하는 핵심 연산
- 커널(kernel)과 Convolution 연산
- 이미지(input)와 커널(kernel = filter) 간의 convolution 연산으로 처리

- 2차원 이미지 데이터 : 행렬로 표현 ( 행렬의 각 원소는 해당 위치의 이미지 픽셀 값 )
- Convolution kernel : 행렬로 표현
Convolution 연산은 2차원 상에서 연산이 이루어지므로 이미지 데이터를 변형없이 그대로 사용 가능
convolution 연산 과정
- 행렬 내부의 요소들을 요소 별로(element-wise) 곱해서 더함 -> 선형 연산
- kernel을 이미지 영역 내에서 convolution 연산 수행
- 연산 과정 : 커널이 이미지의 노란색 영역에 겹쳐짐


[ Feature Map (Activation Map) ]

- Convolution 연산 결과 : Feature Map 또는 Activation Map 이라 부름 ( Feature Map : 이미지의 특징 추출 )
- 커널과 이미지가 겹치는 영역 : 수용 영역(Receptive Field)
[ 컬러 이미지의 convolution 연산 ]
- 앞선 예시는 이미지의 채널이 1개 → 흑백 이미지
- 컬러 이미지는 채널이 3개 → 커널도 채널을 3개로 준비
- 각 채널 별로 Convolution 연산을 수행하고 각 결과(Feature Map)를 요소별로(element-wise) 더해 하나의 Feature Map을 생성

[ Convolution 연산 확장 ]
- 커널을 여러개 두면 Feature Map도 여러개 생성
- 노란색 행렬 : Filter 1(kernel 1)을 사용한 feature map (3개의 feature map을 더해 하나의 feature map 형성)
- 주황색 행렬 : Filter 2(kernel 2)을 사용한 feature map
- output : 총 2개의 채널을 가지는 feature map 생성

2. Convolutional Neural Network
- 지금까지 사용한 커널들은 학습 가능한 커널 -> 즉, 커널 행렬의 각 값들이 가중치(Weight)
- 이러한 커널들로 이루어진 Layer를 Convolutional Layer라고부름
- 이 Layer들을 쌓아서 CNN을 구성

- 첫번째 convolutional layer : 빨간색 feature map과 파란색 feature map 사이 layer
( 6개의 kernel을 사용하여 두번째 파란색 feature map이 6개의 channel을 가짐 ) - 두번째 convolutional layer : 10개의 kernel을 사용하여 초록색 feature map이 10개의 channel을 가짐
- 하나의 convolutional layer는 여러 개의 channel로 구성될 수 있음 -> 이 layer를 쌓아 CNN 구성
Convolutional Layer
- kernel을 이용하여 이미지에서 feature를 추출하는 layer
- convolutional layer에서 조절할 수 있는 hyperparameter : 커널의 개수, 커널의 크기, stride 등
[ Layer의 역할 ]
- 이미지가 가지는 특정 Feature를 뽑아내도록 커널을 학습
- 커널에 따라 추출하는 Feature를 다르게 학습 (Feture 예시 : 이미지내의 대각선, 원형, 색조 등등)
- 그림에서 행렬의 한칸 = Feature Map 하나의 결과, 즉 총 64개의 chennel이 있음

Convolution 연산과정을 조절하기 위한 Hyper parameter => stride, padding
[ Stride ]
- 커널이 이미지 내에서 이동하는 칸 수를 조절
- 앞선 Convolution 연산에서 보여준 예시는 모두 1칸 ( 아래 그림은 Stride가 2칸일 경우 예시 )

[ Padding ]
- 앞선 예시는 Convolution 연산 결과 Feature Map 사이즈가 계속 줄어듦
- Padding을 추가하여 Feature Map 사이즈가 줄어드는 현상 방지
- 이미지의 테두리 정보도 균일하게 활용 가능
- 주로 padding 에 들어가는 값은 0이며, 이를 zero padding이라 부름

[ Convolutional Layer 의의 ]
- 왜 이미지 특징을 잘 뽑아내는가?
- Convolution 연산은 하나의 커널이 픽셀 간의 정보를 보게 만듦
- 즉, 하나의 커널이 이미지 전체 영역을 학습
- Parameter Sharing
- 커널이 가진 Parameter를 이미지의 모든 영역에서 공유
- Parameter 개수를 FC Layer에 비해 극적으로 줄임 → 과적합방지에유리
- FC layer의 경우) 이미지 1*64, 커널 1*9 라면, 총 64*9개의 가중치 필요
- Convolution Layer의 경우) 이미지 8*8, 커널 3*3 라면, 총 9개(kernel 행렬의 내부 값)의 가중치 필요
[Convolutional Layer 활성화 함수 ]
- Convolution 연산은 선형연산 ( 모두 곱셈과 덧셈으로만 이루어짐 )
- 따라서, FC Layer처럼 비선형성을 추가하기 위해 활성화 함수 사용 (CNN은 주로 ReLU함수 사용)

[ Pooling Layer ]
- CNN에서 거의 항상 같이 쓰이는 Layer
- 채널 별로 연산
- Convolution 연산과는 다르게, 각 채널 별로 수행된 연산을 더하지 않음
- 주역할 : Feature Map의 사이즈를 줄여 Parameter개수를 줄이는 것 → 과적합 조절

- Max Pooling
- 주어진 이미지나 Feature Map을 겹치지 않는 더 작은 영역으로분할
- 위 그림은 각 영역의 크기가 2x2가 되도록 분할
- 각 영역에서 최대값을 뽑아내어 새로운 Feature Map을 구성

- Average Pooling
- Max Pooling과 거의 동일하나, 각 영역의 평균값을 계산하여 새로운 Feature Map을 구성

[ Pooling Layer 정리 ]
- 일반적으로 Max Pooling을 많이 사용 ( Feature Map에 존재하는 Feature 중 가장 영향력이 큰 Feature만 사용 )
- Feature Map의 채널이 여러 개면 각 채널별로 Pooling 연산 수행 (pooling의 결과 채널별로 합치지 않음)
- 추가 Pooling Layer
- Global Average Pooling: 전체 Feature Map에서 하나의 평균값 계산
- Global Max Pooling: 전체 Feature Map에서 하나의 최대값을 계산
- 여기선 Global Average Pooling을 많이 사용 (그림의 pooling은 global average pooling)

[ Classifier ]
- CNN은 일반적으로 이미지 분류 목적으로 사용
- Feature Map을 Fully-connected Layer에 통과시켜 분류 수행
- 이를 위해 Feature Map을 1차원으로 변형
- 1차원으로 변형하는 방법 :
- feature map을 단순히 flatten 함
- global average pooling 등의 방법 이용함 (channel의 개수 = 벡터의 길이)
- 1차원으로 변형하는 방법 :

[ Tensorflow 로 Convolution Layer 구현 ]
import tensorflow as tf
from tensorflow import keras
''' 방법 1 : Tensorflow로 conv2d 사용 '''
# input : 1로 구성된 3x3 크기의 간단한 행렬 (3x3 x1 이미지가 1개)
inp = tf.ones((1, 3, 3, 1))
# Filter : 1로 가득찬 2x2의 크기를 가진 행렬
filter = tf.ones((2, 2, 1, 1))
# stride : [높이, 너비]의 형식으로 입력 - 1칸씩 이동하도록 1, 1을 입력
stride = [1, 1] # [높이, 너비]
# 준비된 입력값, filter, stride로 Convolution 연산 수행 (padding을 'VALID'으로 설정 = 패딩을 하지 않음)
output = tf.nn.conv2d(inp, filter, stride, padding = 'VALID')
print(output)
# [[ [[4.] [4.]]
# [[4.] [4.]] ]], shape=(1, 2, 2, 1), dtype=float32)
## 결과 : Padding이 없는 상태에서 Convolution을 수행하니 입력의 크기(3x3)보다 출력의 크기(2x2)가 작아짐
# padding옵션을 'VALID'가 아닌 'SAME'으로 설정 (입력과 출력의 형태가 같도록 패딩을 적용)
output = tf.nn.conv2d(inp, filter, stride, padding = 'SAME')
print(output)
# [[ [[4.] [4.] [2.]]
# [[4.] [4.] [2.]]
# [[2.] [2.] [1.]] ]], shape=(1, 3, 3, 1), dtype=float32)
## 결과 : Convolution Layer에서 padding을 'SAME'으로 설정하면 여러번 연산해도 크기는 줄어들지 않음
''' padding을 직접 설정해서 전달 '''
# 위,아래,오른쪽,왼쪽에 padding을 각각 한 칸씩 추가
padding = [[0, 0], [1, 1], [1, 1], [0, 0]] # [[0, 0], [pad_top, pad_bottom], [pad_left, pad_right], [0, 0]]
output1 = tf.nn.conv2d(inp, filter, stride, padding = padding)
print(output1)
# [[ [[1.] [2.] [2.] [1.]]
# [[2.] [4.] [4.] [2.]]
# [[2.] [4.] [4.] [2.]]
# [[1.] [2.] [2.] [1.]] ]]
''' 방법 1 : Tensorflow.Keras로 Conv2D 사용 '''
input_shape=(1, 3, 3, 1)
x = tf.ones(input_shape) # 3x3 x1 이미지가 1개 (1, 높이, 너비, 1)
print(x)
y = tf.keras.layers.Conv2D( filters = 1, # 필터의 갯수
kernel_size = [2, 2], # "kernel_size = 2" 와 같은 의미 (높이, 너비)
strides = (1, 1),
padding = 'same', # keras.layers.Conv2D 의 padding은 소문자 'same', 'valid'
activation = 'relu',
input_shape = input_shape[1:]) (x) # 입력 : x
print(y)
# [[ [[0.36910588] [0.36910588] [0.54728895]]
# [[0.36910588] [0.36910588] [0.54728895]]
# [[0.8551657 ] [0.8551657 ] [0.6025906 ]] ]], shape=(1, 3, 3, 1), dtype=float32)
[ Fully-connected Layer를 쌓아 만든 Multilayer Perceptron(MLP) 모델 vs CNN 모델 비교 ]
- 이미지 분류 모델 구현
- 데이터셋 : CIFAR-10 데이터셋
- 각 데이터가 32×32의 크기를 가지는 컬러 이미지로 구성
- 비행기, 자동차, 새 등의 10개의 클래스에 속함
- 학습(Train) 데이터셋은 50000개, 테스트(Test) 데이터셋은 10000개의 이미지가 포함 - 아래 코드에서는
import tensorflow as tf
from tensorflow.keras import layers, Sequential, Input
from tensorflow.keras.optimizers import Adam
import numpy as np
import matplotlib.pyplot as plt
SEED = 42
def load_cifar10_dataset():
train_X = np.load("./dataset/cifar10_train_X.npy")
train_y = np.load("./dataset/cifar10_train_y.npy")
test_X = np.load("./dataset/cifar10_test_X.npy")
test_y = np.load("./dataset/cifar10_test_y.npy")
train_X, test_X = train_X / 255.0, test_X / 255.0
return train_X, train_y, test_X, test_y
''' MLP 모델 '''
def build_mlp_model(img_shape, num_classes=10):
model = Sequential()
model.add(Input(shape=img_shape))
model.add(layers.Flatten()) # 2차원 이미지 -> 1차원
model.add(layers.Dense(units=4096, activation='relu'))
model.add(layers.Dense(units=1024, activation='relu'))
model.add(layers.Dense(units=256, activation='relu'))
model.add(layers.Dense(units=64, activation='relu'))
model.add(layers.Dense(units=num_classes, activation='softmax'))
return model
''' CNN 모델 '''
def build_cnn_model(img_shape, num_classes=10):
model = Sequential()
model.add(layers.Conv2D(filters=16, kernel_size=(3,3), padding='same', activation='relu', input_shape = img_shape)) # convolution layer는 처음에 input_shape 지정해야 함
model.add(layers.Conv2D(filters=32, kernel_size=(3,3), padding='same',activation='relu'))
model.add(layers.MaxPool2D(pool_size=(2,2), strides=(2,2))) # pooling : 이미지 사이즈가 2배로 줄도록 설정
model.add(layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', strides=(2,2),activation='relu')) # strides=(2,2)이므로 feature map가 가로,세로로 2배씩 줄어들음 - maxpooling과 같은 효과
model.add(layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', strides=(2,2),activation='relu'))
model.add(layers.MaxPool2D(pool_size=(2,2), strides=(2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(units=128, activation='relu')) # fully connected layer 사용
model.add(layers.Dense(units=num_classes, activation='softmax'))
return model
def plot_history(hist):
train_loss = hist.history["loss"]
train_acc = hist.history["accuracy"]
valid_loss = hist.history["val_loss"]
valid_acc = hist.history["val_accuracy"]
fig = plt.figure(figsize=(8, 6))
plt.plot(train_loss)
plt.plot(valid_loss)
plt.title('Loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['Train', 'Valid'], loc='upper right')
plt.savefig("loss.png")
fig = plt.figure(figsize=(8, 6))
plt.plot(train_acc)
plt.plot(valid_acc)
plt.title('Accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['Train', 'Valid'], loc='upper left')
plt.savefig("accuracy.png")
def run_model(model, train_X, train_y, test_X, test_y, epochs=10):
optimizer = Adam(learning_rate=0.001)
model.summary()
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
hist = model.fit(train_X, train_y, epochs=epochs, batch_size=64, validation_split=0.2, shuffle=True, verbose=2)
plot_history(hist)
test_loss, test_acc = model.evaluate(test_X, test_y)
print("Test Loss: {:.5f}, Test Accuracy: {:.3f}%".format(test_loss, test_acc * 100))
return optimizer, hist
def main():
tf.random.set_seed(SEED)
np.random.seed(SEED)
train_X, train_y, test_X, test_y = load_cifar10_dataset()
img_shape = train_X[0].shape
mlp_model = build_mlp_model(img_shape)
cnn_model = build_cnn_model(img_shape)
print("=" * 30, "MLP 모델", "=" * 30)
run_model(mlp_model, train_X, train_y, test_X, test_y)
print()
print("=" * 30, "CNN 모델", "=" * 30)
run_model(cnn_model, train_X, train_y, test_X, test_y)
if __name__ == "__main__":
main()
[ 코드 결과 해석 ]
## MLP 모델
Test Loss: 1.87062, Test Accuracy: 34.200%
## CNN 모델
Test Loss: 1.35545, Test Accuracy: 50.800%

- loss와 accuracy를 비교했을 때, CNN 모델이 MLP 모델보다 성능이 좋음
- Trainable params = 실제 모델 학습에 사용되는 파라미터의 개수
- MLP 모델에서 필요한 parameter의 개수(17,061,834)보다 CNN 모델에서 필요한 parameter의 개수(94,698)현저히 작음




3. 대표적인 CNN 모델
- LeNet (1990)
- 우편번호 인식을 위한 모델
- subsampling은 pooling과 동일한 역할 수행
- 마지막에 full connection (FC layer)를 통해 분류기 형성

- AlexNet (2012)
- 2012년 ImageNet Challenge 우승 → 기존 모델의 성능을 큰폭으로 상회
- ReLU 활성화 함수 소개
- 딥러닝 모델 학습에 GPU를 활용 → 이후로 대부분의 딥러닝 모델은 GPU로 학습
- 당시 GPU의 한계로, 2개의 GPU를 사용했기 때문에 모델로 2개로 나눠서 학습함

- VGGNet (2014)
- 커널 사이즈를 모두 3x3으로 통일
- Parameter수 증가를 억제하면서 모델 층을 더 많이 쌓을 수 있게 됨
- 층이 많을수록(즉,모델이 깊을수록)일반적으로 성능이 향상됨

[ 16개의 layer로 이루어진 VGGNet, VGG-16 구현 ]
- VGGNet부터는 Layer 개수가 많이 늘어남에 따라 Block 단위로 모델을 구성.
- 각 Block은 2개 혹은 3개의 Convolutional Layer와 Max Pooling Layer로 구성.
- parameter가 존재하는 layer만 layer 개수를 셈 - pooling, flatten layer는 layer 개수에 포함 X
- trainable params가 138,357,544 개 -> 딥러닝 층이 깊어질수록 필요한 parameter 개수 기하급수적으로 증가
import tensorflow as tf
from tensorflow.keras import Sequential, layers
def build_vgg16():
model = Sequential()
# 첫번째 Block
model.add(layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', activation='relu', input_shape=(224, 224, 3)))
model.add(layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(2)) # pooling : 이미지 사이즈가 2배로 줄도록 설정
# 두번째 Block
model.add(layers.Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(2))
# 세번째 Block
model.add(layers.Conv2D(filters=256, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.Conv2D(filters=256, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.Conv2D(filters=256, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(2))
# 네번째 Block
model.add(layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(2))
# 다섯번째 Block
model.add(layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.Conv2D(filters=512, kernel_size=(3,3), padding='same', activation='relu'))
model.add(layers.MaxPooling2D(2))
# Fully Connected Layer
model.add(layers.Flatten())
model.add(layers.Dense(4096, activation="relu"))
model.add(layers.Dense(4096, activation="relu"))
model.add(layers.Dense(1000, activation="softmax"))
return model
def main():
model = build_vgg16()
model.summary()
if __name__ == "__main__":
main()

- ResNet (2015)
- Layer 개수를 최대 152개까지 늘림
- 깊은 모델에서 필연적으로 나타나는 현상 : Vanishing Gradient
- Vanishing Gradient (기울기소실)
- 역전파 과정에서 기울기 값이 점점 작아지다 0에 수렴하면서 발생
- 모델 학습에 오랜 시간이 걸리거나 아예 학습이 멈추게 됨
- 이를 해결하기 위해 residual connection 구조가 추가됨
- Residual connection : vanishing gradient 문제를 해결하기 위한 구조
- residual connection을 사용하려 layer 개수를 극적으로 늘림
- 기존 convolutional layer들을 우회하는 연결
- 입력 Feature Map(x)이 우회로를 통과하여 Convolutioinal Layer의 Feature Map( $ F(x) $ )과 더해짐
- 기울기 값이 항상 1 이상이 되어 기울기 소실 문제 방지

- 그림의 weight layer가 convolution layer와 동일한 역할
- pooling layer는 가중치 개수에 영향을 주지 않으므로, 그림에서는 생략했음
[ ResNet 구현 ]
- Residual Connection은 보통 ResNet의 각 Block 단위로 구현. 따라서 일반적으로 Residual Connection을 가지는 부분을 Residual Block이라 하여 Block 단위로 구현한 후에 이들을 연결하는 식으로 모듈화 하여 전체 모델 구현
import tensorflow as tf
from tensorflow.keras import layers, Model, Sequential
''' Residual Block 모듈 '''
class ResidualBlock(Model):
def __init__(self, num_kernels, kernel_size):
super(ResidualBlock, self).__init__()
# 2개의 Conv2D Layer
self.conv1 = layers.Conv2D(filters=num_kernels, kernel_size=kernel_size, padding='same',activation='relu')
self.conv2 = layers.Conv2D(filters=num_kernels, kernel_size=kernel_size, padding='same',activation='relu')
# Relu Layer : 활성화 함수도 layer형식으로 취급 가능
self.relu = layers.Activation("relu")
# Add Layer : 두개의 텐서를 더하는 layer
self.add = layers.Add()
def call(self, input_tensor):
x = self.conv1(input_tensor) # 1번의 convolution layer 결과
x = self.conv2(x) # 2번의 convolution layer 결과
x = self.add([x, input_tensor]) # 두 값을 더하는 과정 (original + 2개의 convolution 결과)
x = self.relu(x) # relu layer 구현
return x
def build_resnet(input_shape, num_classes):
model = Sequential()
model.add(layers.Conv2D(64, kernel_size=(3, 3), padding="same", activation="relu", input_shape=input_shape))
model.add(layers.MaxPool2D(2))
model.add(ResidualBlock(64, (3, 3)))
model.add(ResidualBlock(64, (3, 3)))
model.add(ResidualBlock(64, (3, 3)))
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(num_classes, activation="softmax"))
return model
def main():
input_shape = (32, 32, 3)
num_classes = 10
model = build_resnet(input_shape, num_classes)
model.summary()
if __name__=="__main__":
main()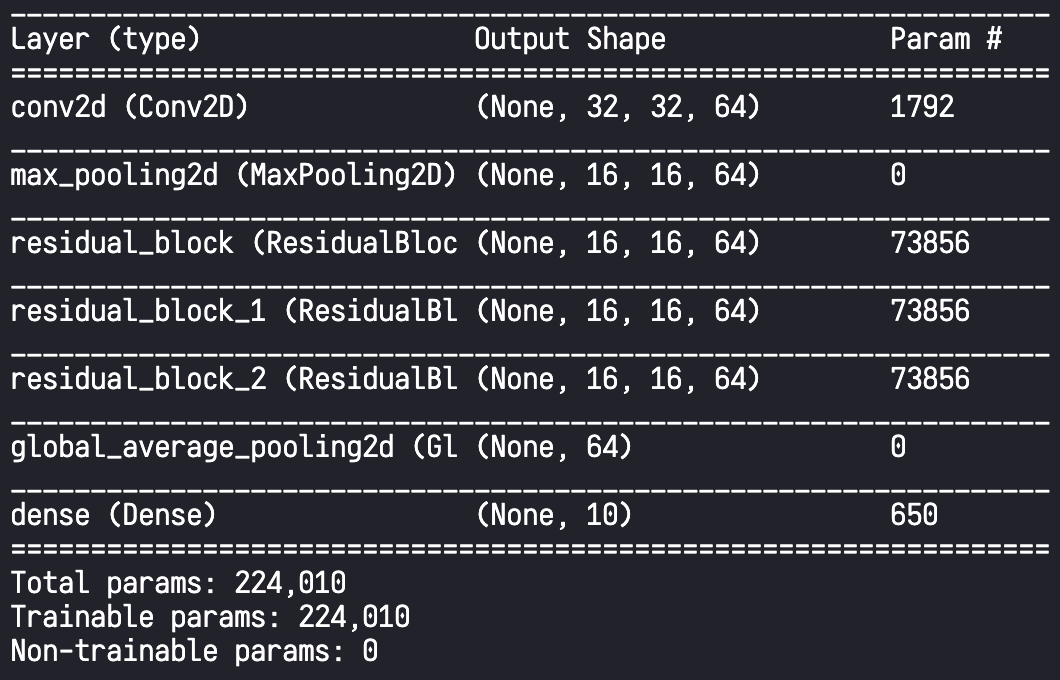
지금까지 나온 모델은 모두 분류 모델임. 분류 작업이 아닌 경우에 사용하는 모델은?
- 일반적으로 분류 모델과 유사하게 CNN 구성
- but, 모델의 출력값, 손실함수, 데이터셋 구성 등이 완전히 다르게 이루어짐
- 예) YOLO(객체 인식), R-CNN(객체 인식), U-Net(이미지 segmentation) 등
'🤖 AI > Deep Learning' 카테고리의 다른 글
| [딥러닝] 9. LSTM, GRU (1) | 2024.07.10 |
|---|---|
| [딥러닝] 8. RNN (1) | 2024.07.01 |
| [딥러닝] 6. 딥러닝 모델 학습의 문제점 pt.3 : 과적합 (0) | 2024.06.22 |
| [딥러닝] 5. 딥러닝 모델 학습의 문제점 pt.2 : 기울기 소실, 가중치 초기화 방법 (2) | 2024.06.12 |
| [딥러닝] 4. 딥러닝 모델 학습의 문제점 pt.1 : 최적화 알고리즘 (0) | 2024.06.10 |



